3 Common Regex Mistakes and How to Fix Them
Regular expressions (regex) are incredibly powerful, but they can also be tricky to master. Even experienced developers make common mistakes that lead to unexpected results. In this post, we’ll cover three simple regex mistakes, provide examples of how they happen, and show how to fix them effectively.
1. Forgetting to Escape Special Characters
The mistake: Some characters in regex have special meanings, like . (matches any character), * (matches zero or
more of the previous character), + (one or more), | (or), and ? (optional). If you want to search for them as
literal characters, you need to escape them with a backslash (\).
Example:
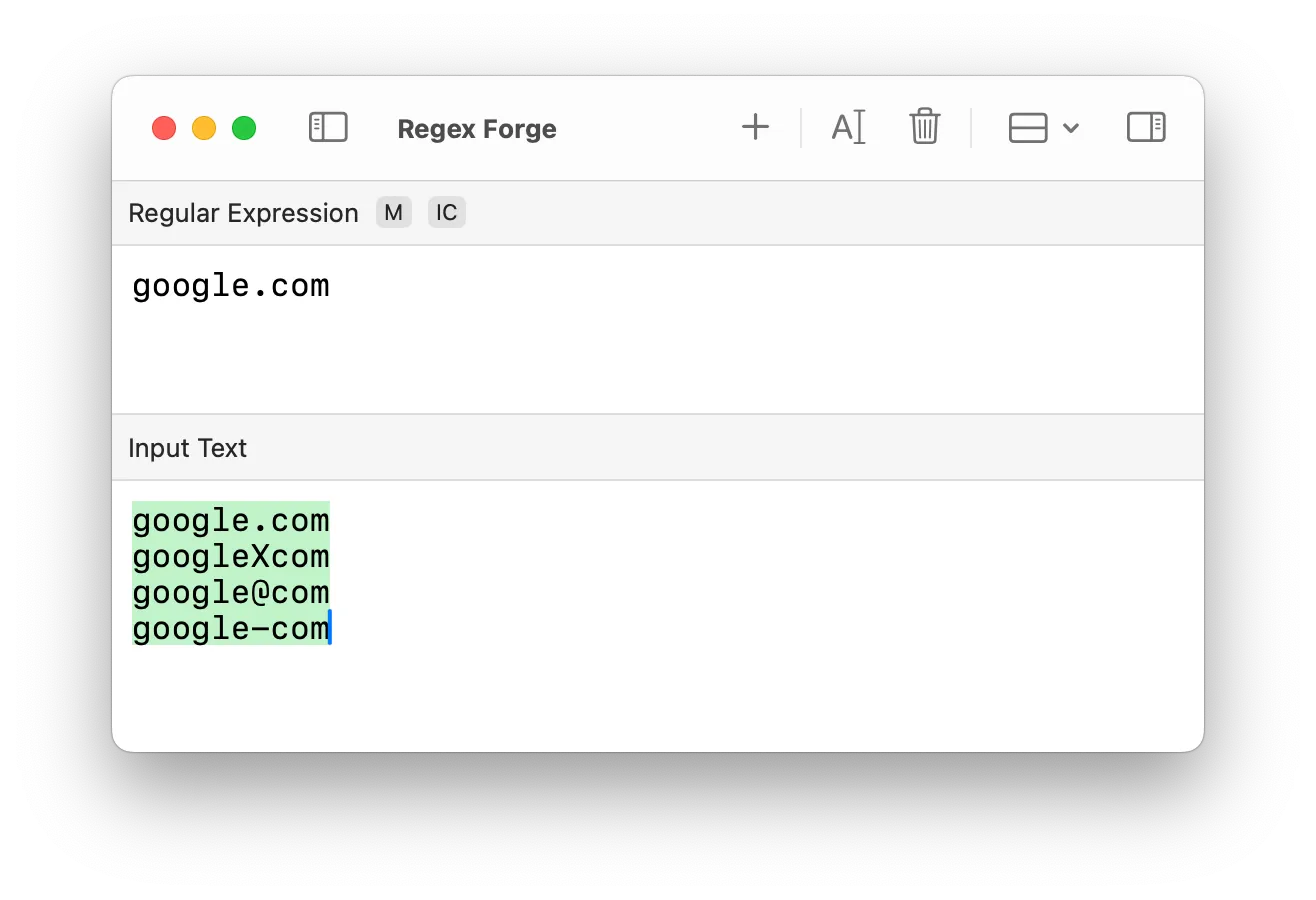
regex: google.com
text: googleXcom → (matches incorrectly)Here, . means “any character,” so google.com also matches googleXcom, google@com, google-com, etc.
Another example: Say you want to match the price in $10.99 but write:
regex: $10.99
text: I paid $10.99 → (error)This doesn’t work as expected because $ has a special meaning (it anchors to the end of a string).
The fix: Escape special characters with \:
regex: google\.com
text: google.com → (correct match)And for price matching:
regex: \$10\.99
text: I paid $10.99 → (correct match)Now, the patterns correctly match only the intended text.
2. Using .* When You Really Need .*?
The mistake: .* is greedy, meaning it matches as much as possible, often more than expected.
Example:
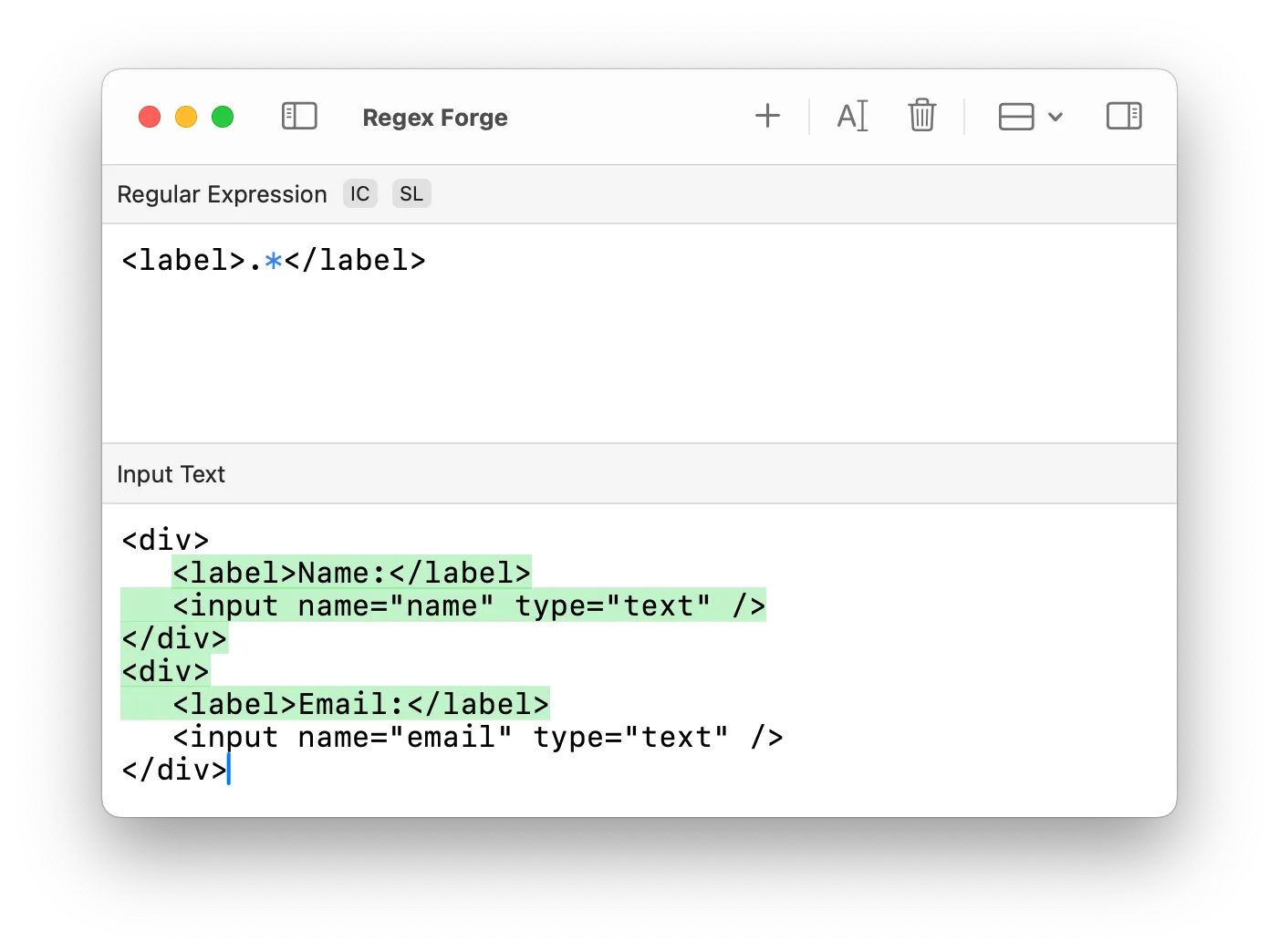
regex: <b>.*</b>
text: <b>bold</b><b>text</b> → (matches everything)This regex captures everything between the first <b> and the last </b>, not just the first pair.
Another example: Let’s say you need to extract an HTML tag’s content:
regex: <title>.*</title>
text: <title>My Page</title><title>Another</title>This will match:
<title>My Page</title><title>Another</title>instead of just the first title tag.
The fix: Use .*? for lazy matching to stop at the first match:
regex: <b>.*?</b>
text: <b>bold</b><b>text</b> → (correct match: only <b>bold</b>)And for the title tag issue:
regex: <title>.*?</title>
text: <title>My Page</title><title>Another</title>This ensures only the first <title> tag is matched, preventing excessive capture.
3. Forgetting Word Boundaries
The mistake: If you’re searching for a specific word, regex might match it inside other words unless you use word boundaries.
Example:
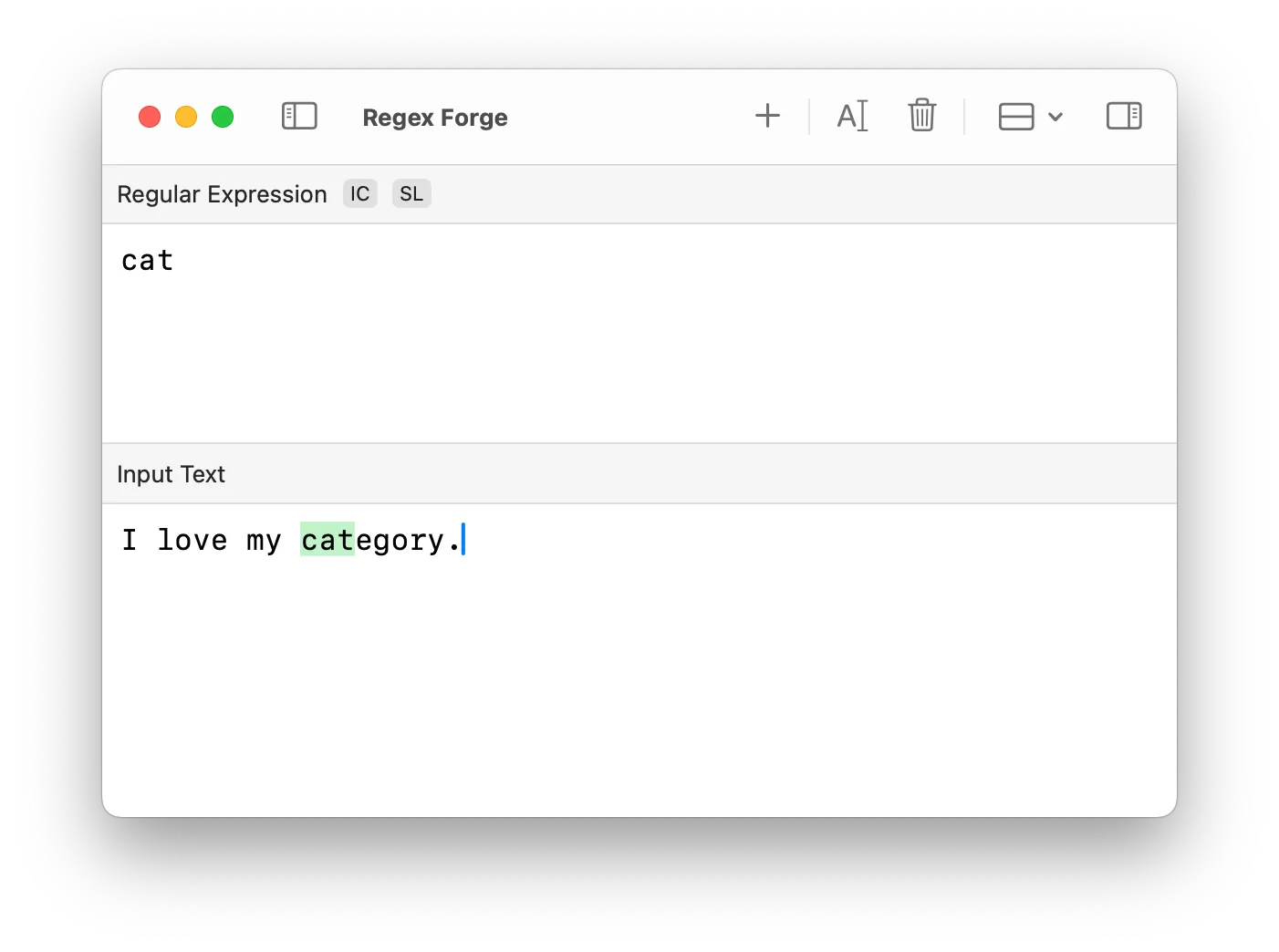
regex: cat
text: I love my category. → (matches "cat" inside "category")Here, cat is found inside “category,” which is likely unintended.
Another example: Suppose you want to find the word “red” but accidentally match words like “redefine” or “predator”:
regex: red
text: A redefine function can be tricky. → (matches "red" in "redefine")The fix: Use \b to match whole words only:
regex: \bcat\b
text: I love my cat. → (correct match: "cat" only)And for the “red” example:
regex: \bred\b
text: My favorite color is red. → (correct match: "red" only)This prevents unintended matches by ensuring the search term stands alone as a word.
Final Thoughts
These three simple mistakes can lead to unexpected regex behavior, but they’re easy to fix once you know what to watch out for. By properly escaping special characters, using lazy matching when needed, and adding word boundaries, you’ll avoid common regex pitfalls and write more accurate patterns.
If you’re looking for an easy way to test, debug, and visualize your regex patterns, Regex Forge is the perfect tool. It offers an interactive environment where you can instantly see how your regex behaves, making it easier to learn and refine your expressions.
Ready to Master Regex?
Effortless regex. Boost your productivity and simplify your workflow.